
Building a Train Horn Detection Neural Network
Written by
Chris Laan
automotive
February 11, 2020

The suspect in question
I happen to live near a train, this train honks quite a bit throughout the day and night. Also, the train tracks cut through the neighborhood across five or six streets without any automatic gates to prevent crossing. So before the train can cross each street, it is required to blast the horn for a while. So as a therapeutic exercise I decided to try and detect and quantify the honking behavior. I was also hoping for a way to check in real-time if the train is blocking the street. It can be quite annoying if you're in a rush and get stuck behind the train. This post details my weekend project to do this.
After a weekend of hacking, I was able to get an accurate train horn detector running live from a mic outside my window. You can get the code to train the network on github.
I also post the detections live online here: BywaterTrain.com
I'm not familiar with audio classification, so I did some quick googling in the hope that someone else had solved a similar problem already. My constraints were that the model run fast enough to process live audio from the mic. Since I did not have a ton of labeled data, I was looking for an "ImageNet of audio" type of network I could fine tune on a very small dataset. Yamnet from google seemed to check a few of those boxes so I went with that.
From google: "YAMNet is a pretrained deep net that predicts 521 audio event classes based on the AudioSet-YouTube corpus, and employing the Mobilenet_v1 depthwise-separable convolution architecture." So the fact that it uses Mobilenet_v1 means it's probably fast enough, and being pre-trained on a large dataset is even better.
The AudioSet-YouTube dataset from google interesting on its own. Created from the audio within youtube clips, you can download it as .csv files that point to the time within the youtube video, or as a 128-bit feature vector as output by their VGG-style architecture (see here).
The dataset already contained various train related categories, but the accuracy it gave on my dataset was not good enough, so I decided to fine tune an additional network on top of the yamnet output.
If your data is one of the 521 classes, you might be able to directly use the yamnet output and not have to train anything at all.
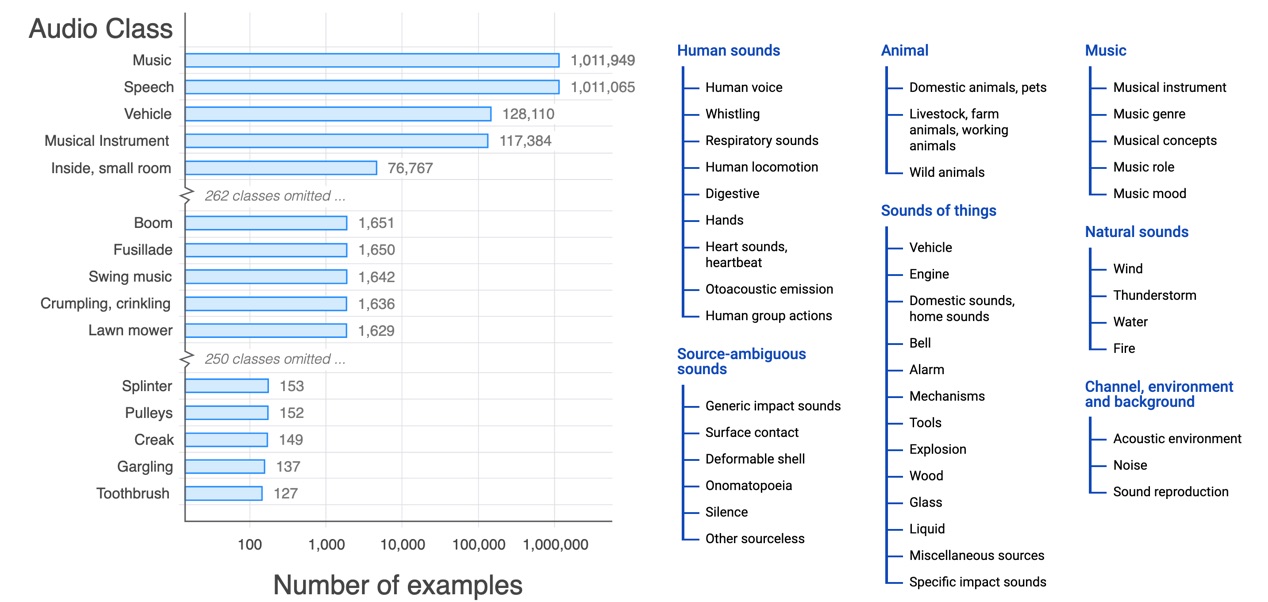
Youtube Audio Dataset
I recorded short audio clips from my computer's microphone and labeled them as either positive (train horn) or negative (everything else). I ended up with around 200 short clips total, which isn't a lot, but seemed to work well enough for fine-tuning.
The yamnet model processes audio in 0.96 second windows, so I chopped up my recordings into chunks of that length. For each chunk, I ran it through yamnet to get the 1024-dimensional embedding vector, which I then used as input to train a simple classifier on top.
The final model works surprisingly well! It can detect train horns in real-time with high accuracy. False positives are rare, and it catches most of the train horn events throughout the day.
I've been running it continuously on a Raspberry Pi with a cheap USB microphone, logging all detections to a database. The data shows some interesting patterns about when trains pass through the neighborhood.
Check out the live detections at BywaterTrain.com!
The training code and model architecture are available on GitHub: github.com/laanlabs/train_detector
Feel free to adapt this approach for detecting other sounds - car alarms, construction noise, or whatever audio events you're interested in tracking!
Get the markdown source for offline reading